are we locked into P(doom)?

starting with the conclusion
earlier this year I was a part of the latest cohort at AI safety camp (AISC). the project I had joined — Investigating assumptions of the doom debate — had a goal to build a probabilistic assumption tree for AI doom arguments.
several members made versions of the tree, but the one that we collectively worked on, started from a root node “Dangerous AI occurs.” one branch — “model capacity”broke down into a dozen subnodes, from inference and reasoning capability, to model optimization. the other branch —“external environment” — was less developed, with only two nodes: “conducive human policy,” and “sustained capacity for development.” now, both of these could reasonably be argued as already certain, making assigning probabilities to them all but meaningless. nonetheless, this was the branch I took on that sent me down a divergent path from the rest of the team: why was the environment being treated as an afterthought?
it reflected something at the core of the canonical AI doom argument: it is fundamentally grounded around the agent — what it can do, what it wants, whether it could become too powerful to control. but the environment, in which harm actually occurs, barely appears, treated as a passive backdrop, instead of as an active component of the risk.
three conditions
my earliest version of the tree started from first principles: what are the necessary conditions for AI to cause existential harm?
I landed on three:
AI is sufficiently capable
it cannot be stopped
the harm cannot be recovered from
these three conditions would eventually survive dozens of iterations complementing a complete paradigm shift in how I thought about P(doom).
going down the beaten path
I dug into the canonical AI safety concepts: misalignment, instrumental convergence, orthogonality, goal specification, capability thresholds. mapping this to a tree quickly became a convoluted mess. every decomposition led to questions about the definition of the terms we were using—what counts as a goal? does indifference count as misalignment? which capabilities does a system need to be considered dangerous?
our trees were sprawling with over a dozen nodes full of these conceptual claims rather than verifiable ones. it hit me: the mapping wasn’t at an impasse because the questions were hard, but because we hadn’t even agreed on what we were talking about.
taking a step back, I assessed what kind of claim each node was making, and categorized them:
empirical claims are about the current state of the world; true or false; verifiable (e.g. “nuclear weapons exist”)
conditional claims depend on future events; a forecast not an observation; estimable but carry uncertainty (e.g. “AI capability will exceed human-level within a decade.”)
definitional claims are concepts stated as facts; not verifiable so you can’t meaningfully assign a probability to it (e.g. “Sufficiently capable AI will develop instrumental goals.”)
the canonical doom argument relies heavily on definitional claims treated as empirical ones. but probability estimates on definitional claims are just intuitions cosplaying in mathematical structure. we cannot build a meaningful probability tree until we’ve resolved what terms mean. the definitions are a prerequisite.
coming to terms
the root node of the canonical tree says ‘dangerous AI occurs,’ but dangerous how, to what? unpacking it revealed that the terms are hierarchically nested: AI optimizes, optimization affects something, that something is human welfare. ‘dangerous’ becomes ‘harmful’ once you specify what it’s harmful to.
“human welfare” encompasses three conditions that we want to preserve or improve: human life, the environment that sustains human life, and what human life has materially built (infrastructure, civilization). these are the targets of optimization, and the things through which harm, at doom scale, is actualized.

“harmful” is then defined relative to humans’ ability to stop or reverse adverse effects on human welfare.
instead of being a property of the AI, it’s a relational property between the optimization and the corrective capacity of the environment it’s operating in.
so under these definitions, harmful AI already exists — recommendation algorithms erode the social contract. autonomous trading bots create financial fragility. finite resource extraction is scaling to civilization levels for AI infrastructure.
the doom debate is often framed as some future risk from AGI or superintelligence, but the risk from AI is already here, which is why we need to talk about trajectory.
configuration, not agency
I decided to ask a different question.
the canonical approach asks: what properties must AI have to be dangerous? this got us stuck in debates about capability thresholds, goal specification, alignment definitions.
what if instead we start from: what makes an environment vulnerable to catastrophic harm, and how does AI push toward those conditions?
AI dropped from the top of the tree to the bottom. it went from being an assumed dangerous agent to being one mechanism among many that could push environmental conditions toward doom.
danger is not a property of the AI, but rather a property of the configuration between optimization and environment.

the tree became pathway agnostic—it didn’t care whether harm came from a misaligned superintelligence, a misused system, or the compound effects of thousands of deployed bots with complex interactions.
the canonical argument treats the external world as a passive recipient of the agent’s actions. the environment is where harm happens, but it’s altogether missing from the formalization. ignoring it means ignoring most of the actual risk surface, which is in itself dynamic and antifragile.
the formalization
E — environment, internally coupled such that changes propagate to K
K — dangerous conditions, a subset of E
K₀ — current state of K at time t
K+ — K worsening
t — point in time at which K and R₀ are sampled
R₀ — rate of change of K at t (current trajectory)
Rc — rate at which corrective capacity can negate K+
O — optimization, preference ordering of actions to change E
M — K is mutable (accessible, changeable)
C — O sufficient to mutate K (directly or through E)
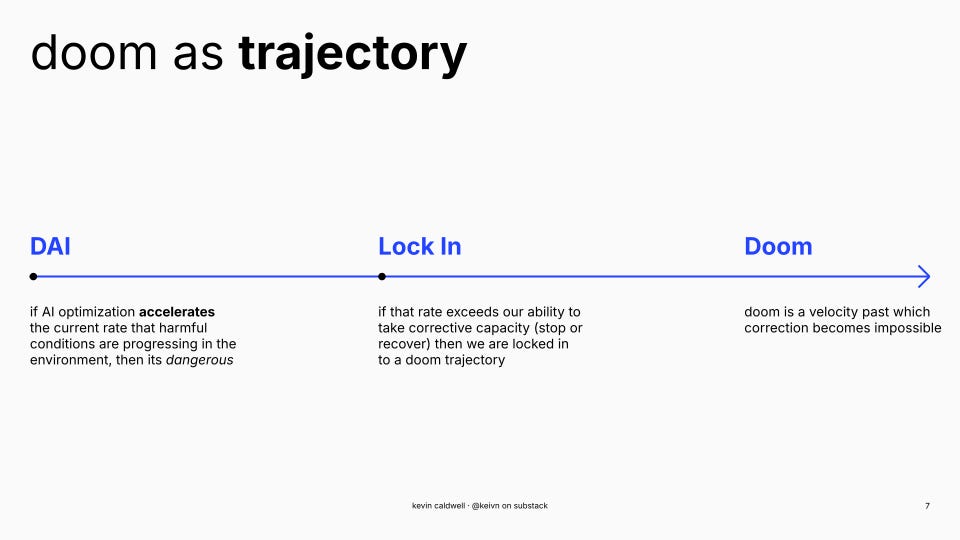
DAI = AI where K+ | O > R₀ — optimization accelerates worsening beyond current trajectory
Lock in = K+ > Rc — worsening outpaces corrective capacity
Doom = DAI ∧ Lock in
deliberate design decisions:
E is internally coupled. optimization doesn’t need to target K directly. O could change some other part of E and have effects cascade to K.
R₀ already includes existing AI effects. it’s the current rate of change of K, including all existing pressures. DAI asks whether additional optimization makes R₀ worse.
Lock in is agent-agnostic. it’s purely about whether the rate of worsening exceeds corrective capacity, regardless of source.
from threshold to trajectory
the formalization initially included θ, an irrecoverability threshold. doom occurred when K crossed θ, but any threshold is debatable.
to solve this I reframed P(doom) as a trajectory you can’t get off.
at any snapshot in time, dangerous conditions have a state and a rate of change. AI is dangerous if it accelerates that rate. lock-in is when corrective capacity can’t keep up. the question becomes purely about whether or not the worsening is faster than the correction (and if that gap is widening). we’re looking at the probability of a condition instead of an event.
P(Doom) = P(M) × P(C) × P(Lock in)
the tree
Doom — D = DAI ∧ Lock in
├── AI increases P(Doom) — DAI = K+ | O > R₀
│ ├── Dangerous conditions are changeable — M
│ └── Optimization sufficient to change them — C
└── Lock in — K+ > Rc
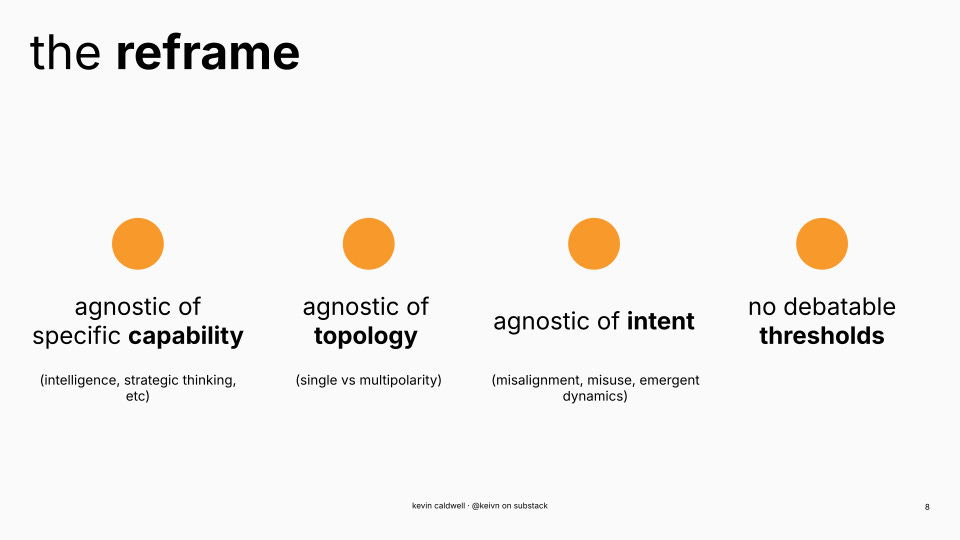
what this resolves
agnostic of intent — if optimization makes K worse, it’s DAI regardless of why
agnostic of architecture — single agent, swarm, aggregate effects
agnostic of specific capabilities — C asks whether optimization can move K, not which capabilities enable it
no debatable thresholds
what remains open
attribution — we can’t empirically isolate AI’s contribution to the rate of change from other pressures (e.g. climate, geopolitics, etc) that moves K.
this is meant for making a confidence estimate, not a forecast.
the app
this formalization was implemented as an interactive tool with two modes:
single scenario
select a risk vector (misaligned, misuse, emergent)
select a substrate (human life, sustaining environment, infrastructure)
set two snapshots in time with confidence sliders for each node
see P(doom) at each snapshot, which node moved most, and a trajectory chart
all trajectories
all nine configurations are displayed simultaneously in a matrix
click any cell to adjust its sliders
an envelope chart shows the collective trajectory as a band
bottom edge is the most optimistic scenario
top edge is the most pessimistic
median line through the middle
band width shows how much your assumptions matter
band height shows how bad things are
the tool can be found here at: https://kvncaldwll.github.io/AISC-P-Doom-Tool/
connecting the dots
my first stab at mapping to the tree was the three conditions: sufficiently capable, cannot be stopped, cannot recover from the harm. dozens of iterations later, those three conditions survived, and became more precisely defined. “sufficiently capable” became M ∧ C — dangerous conditions are changeable and optimization is sufficient to change them. “cannot be stopped” and “cannot recover” merged into lock-in — the rate of worsening outpaces corrective capacity.
everything, from the definitions audit, the environment-first inversion, the dangerous configuration framing, the trajectory reframe — was the process of making those three intuitions rigorous.
developed during AISC, cohort 11, Project 19 - Investigating assumptions of the doom debate. the environment-first framework, formalization, notation, and tool are independent contributions. the project context and team conversations informed the development.